1700508210
1700508211

1700508212
1700508213
1700508214

1700508215

1700508216

1700508217

1700508218

1700508219

1700508220

1700508221

1700508222
前半部分很容易理解:如果分类预测与训练时的分类一致,其值就是的值就是0;相反,如果分类预测与训练时的分类不一致,其值就是的值就是1。后半部分叫作正则化项,λ是系数,叫作w的L2范数(实际上就是)。
1700508223
1700508224

1700508225
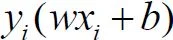
1700508226
正则化项在很多机器学习损失函数中都可以看到,这是一种为了降低结构风险而设置的“损失值”。由统计得到的这个部分的损失称为经验风险,后面的正则化项称为结构风险。尤其是在这种模型中,w按比例扩大不会影响分类结果,我们又希望得到一个w尽可能小的超平面描述来保证其简洁,且不会由于w过大而对噪声敏感进而产生过拟合现象。这种对模型进行优化的思路同样适用于其他分类模型。
1700508227
1700508228

1700508229
合页损失函数的图形如图11-35所示,横轴表示间隔函数1-y(wx+b),纵轴表示损失函数的值,还有一个用来做对比的0-1损失函数。虽然0-1损失函数对损失的解释更为直接,但是由于它有不可导的地方,而且可导的地方导数都是0,所以优化这种损失函数非常困难,这才使用了合页损失函数——从形状上来看,确实像一片打开的合页。合页损失函数在分类正确的时候损失才是0,否则损失是。所以,合页损失函数的优点是分类要求更高,当确信度足够高的时候损失才会下降为0。
1700508230
1700508231

1700508232
1700508233
1700508234
图11-35 合页损失函数
1700508235
1700508236
如果线性不可分,在SVM机器学习算法中会使用一种叫作“核函数”(Kernel)的函数对数据进行升维操作,这也是对非线性分类问题的处理。
1700508237
1700508238
核函数是一种技巧,通过把当前的x向量以一个函数K(x, z)映射到高维空间,让K(x, z)映射后的可以用于分类的超曲面方程在低维空间中仍然呈现超平面的形态。
1700508239
1700508240

1700508241
1700508242
1700508243
就是一个想定的核函数形态。
1700508244
1700508245

1700508246

1700508247
将K(x, z)定义为函数与的内积。其最直观的例子就是在二维空间里假设有一个椭圆能够把空间划分为两部分(这是线性不可分的),椭圆的方程为
1700508248
1700508249

1700508250
1700508251
1700508252
定义
1700508253
1700508254

1700508255
1700508256
1700508257
则原来的椭圆方程就可以退化为
1700508258
1700508259
