1700536184
基于词袋模型或N-gram模型的文本表示模型有一个明显的缺陷,就是无法识别出两个不同的词或词组具有相同的主题。因此,需要一种技术能够将具有相同主题的词或词组映射到同一维度上去,于是产生了主题模型。主题模型是一种特殊的概率图模型。想象一下我们如何判定两个不同的词具有相同的主题呢?这两个词可能有更高的概率同时出现在同一篇文档中;换句话说,给定某一主题,这两个词的产生概率都是比较高的,而另一些不太相关的词汇产生的概率则是较低的。假设有K个主题,我们就把任意文章表示成一个K维的主题向量,其中向量的每一维代表一个主题,权重代表这篇文章属于这个特定主题的概率。主题模型所解决的事情,就是从文本库中发现有代表性的主题(得到每个主题上面词的分布),并且计算出每篇文章对应着哪些主题。
1700536185
1700536186
知识点
1700536187
1700536188
pLSA(Probabilistic Latent Semantic Analysis),LDA(Latent Dirichlet Allocation)
1700536189
1700536190
问题1 常见的主题模型有哪些?试介绍其原理。
1700536191
1700536192
难度:★★☆☆☆
1700536193
1700536194
分析与解答
1700536195
1700536196
■ pLSA
1700536197
1700536198
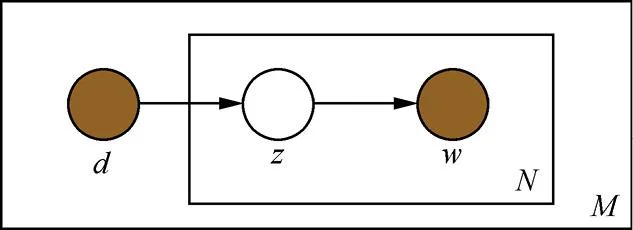
pLSA是用一个生成模型来建模文章的生成过程。假设有K个主题,M篇文章;对语料库中的任意文章d,假设该文章有N个词,则对于其中的每一个词,我们首先选择一个主题z,然后在当前主题的基础上生成一个词w。图6.10是pLSA图模型。
1700536199
1700536200
1700536201
1700536202
1700536203
图6.10 pLSA图模型
1700536204
1700536205

1700536206

1700536207
生成主题z和词w的过程遵照一个确定的概率分布。设在文章d中生成主题z的概率为p(z|d),在选定主题的条件下生成词w的概率为p(w|z),则给定文章d,生成词w的概率可以写成:。在这里我们做一个简化,假设给定主题z的条件下,生成词w的概率是与特定的文章无关的,则公式可以简化为:。整个语料库中的文本生成概率可以用似然函数表示为
1700536208
1700536209

1700536210
,
1700536211
1700536212
(6.26)
1700536213
1700536214
其中p(dm,wn)是在第m篇文章dm中,出现单词wn的概率,与上文中的p(w|d)的含义是相同的,只是换了一种符号表达;c(dm,wn)是在第m篇文章dm中,单词wn出现的次数。
1700536215
1700536216
于是,Log似然函数可以写成:
1700536217
1700536218

1700536219
.
1700536220
1700536221
(6.27)
1700536222
1700536223
在上面的公式中,定义在文章上的主题分布p(zk|dm)和定义在主题上的词分布p(wn|zk)是待估计的参数。我们需要找到最优的参数,使得整个语料库的Log似然函数最大化。由于参数中包含的zk是隐含变量(即无法直接观测到的变量),因此无法用最大似然估计直接求解,可以利用最大期望算法来解决。
1700536224
1700536225
■ LDA
1700536226
1700536227
LDA可以看作是pLSA的贝叶斯版本,其文本生成过程与pLSA基本相同,不同的是为主题分布和词分布分别加了两个狄利克雷(Dirichlet)先验。为什么要加入狄利克雷先验呢?这就要从频率学派和贝叶斯学派的区别说起。pLSA采用的是频率派思想,将每篇文章对应的主题分布p(zk|dm)和每个主题对应的词分布p(wn|zk)看成确定的未知常数,并可以求解出来;而LDA采用的是贝叶斯学派的思想,认为待估计的参数(主题分布和词分布)不再是一个固定的常数,而是服从一定分布的随机变量。这个分布符合一定的先验概率分布(即狄利克雷分布),并且在观察到样本信息之后,可以对先验分布进行修正,从而得到后验分布。LDA之所以选择狄利克雷分布作为先验分布,是因为它为多项式分布的共轭先验概率分布,后验概率依然服从狄利克雷分布,这样做可以为计算带来便利。图6.11是LDA的图模型,其中α,β分别为两个狄利克雷分布的超参数,为人工设定。
1700536228
1700536229

1700536230
1700536231
1700536232
图6.11 LDA图模型
1700536233