1701009206
1701009207
在实际问题当中,需要匹配的关键词及相关联的文章都非常多,所以数据矩阵比较大。为了简化起见,我们这里考虑一个简单的例子,其中,数据矩阵的行m=10,列n=8。即假设一个网站有8个线性代数模块供学习,且每个模块被放置在不同的网页当中。
1701009208
1701009209
可能搜索关键词列表包括以下几个关键词:
1701009210
1701009211
MATLAB、数学建模、案例分析、智能算法、粒子群算法
1701009212
1701009213
遗传算法、鱼群算法、车辆工程、仪器仪表、余胜威
1701009214
1701009215
表7-2为各个关键词出现的频数。
1701009216
1701009217
表7-2 关键词频数表
1701009218
1701009219

1701009220
1701009221
1701009222
表7-2中第3行第5列元素为4,表明关键词“案例分析”在第5个模块中出现了5次。
1701009223
1701009224
令矩阵1对应表7-2中的数据矩阵,则数据矩阵Q的各列由下式决定:
1701009225
1701009226
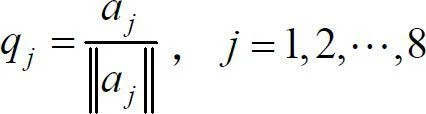
1701009227
1701009228
1701009229

1701009230
为了搜索关键词“遗传算法”、“鱼群算法”和“余胜威”,我们构造一个搜索向量x,它除了对应于搜索关键词“遗传算法”、“鱼群算法”和“余胜威”的3行不是0外,其余元素均为0。为了得到单位搜索向量,将对应于搜索关键词的各行分别乘以。这样,我们就得到数据库矩阵Q及搜索向量x(每一个元素均四舍五入后保留3位小数)为:
1701009231
1701009232

1701009233
1701009234
1701009235

1701009236
如果令,其中θi为单位向量x和θi之间的夹角。
1701009237
1701009238
对于我们的例子,有:
1701009239
1701009240

1701009241
1701009242
1701009243
由于y5=0.635为y中最接近1的元素,说明搜索向量x接近q5的方向,因此模块5应当是最接近搜索标准的一个。接下来最接近搜索标准的一个应该依次是模块6(y6=0.577)和模块3(y3=0.567)。注意到一个模块不包括符合要求的搜索关键词,当且仅当它对应的数据库矩阵列向量与搜索向量x正交。例如,模块1和模块7不包含所需要的搜索关键词,因此有:
1701009244
1701009245

1701009246
1701009247
1701009248
本例说明了一些数据库搜索的基本思想,即利用现代矩阵方法,我们可以对搜索过程进行显著改善,并加快了搜索速度,同时纠正多义词或同义词可能导致的错误。这一新的技术被称为潜语义索引方法,它依赖于矩阵分解及奇异值分解等矩阵方法。
1701009249
1701009250
采用MATLAB软件进行编程计算,编程如下:
1701009251
1701009252
clc,clear,close all %清屏和清除变量 warning off %消除警告 Q=[0,6,3,0,1,0,1,1; %矩阵Q 0,0,0,0,0,5,3,2; 5,4,4,5,4,0,3,3; 6,5,3,3,4,4,3,2; 0,0,0,0,3,0,4,3; 0,0,0,0,3,0,4,3; 0,0,5,2,3,3,0,1; 5,3,3,2,4,2,1,1; 0,0,0,5,1,3,1,0; 0,4,4,3,4,1,0,3]; for i=1:8 Q1(:,i)=Q(:,i)./norm(Q(:,i)); % qj=aj/‖aj‖ end Q1 x=[0,0,0,0,0,1,1,0,0,1]’; x1 = x./sqrt(3) %单位搜索向量
1701009253
1701009254
运行程序如下:
1701009255