1702646290
1702646291
1702646292
1702646293
1702646294
量化数据分析:通过社会研究检验想法 [:1702644750]
1702646295
量化数据分析:通过社会研究检验想法 量化某种关系的大小:回归分析
1702646296
1702646297
描述两个变量关系特征的最简单且常见的方法是在散点图中画出一条通过这些点并“最好地”概括了两个变量之间平均关系的直线。回想中学学过的代数知识,直线可以用一个方程来表示:
1702646298
1702646299
Y=a+b(X) (5.1)
1702646300
1702646301
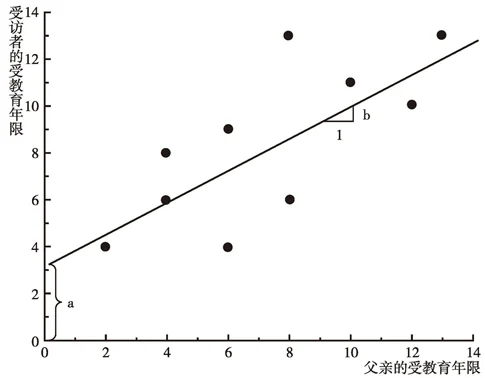
这里,a是截距(intercept)(当X值为0时,Y的取值),b是斜率(slope)(X每个单位的变化所引起的Y的变化量)。图5-2给出了我们关于受访者受教育年限(Y)和父亲受教育年限(X)例子的系数a和b。该图对应的方程可表示为:
1702646302
1702646303

1702646304
1702646305
1702646306
1702646307
1702646308
1702646309
图5-2 受访者受教育年限与父亲受教育年限之间关系的最小二乘回归线
1702646310
1702646311
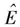
1702646312
这里,代表当假设父亲受教育年限与受访者受教育年限之间的关系是线性的(linear)——假设无论起点如何,父亲的受教育年限每增加一个单位都会使受访者的受教育年限增加一个固定值——时候,父亲受教育年限(EF)的每一水平上别所对应的受访者的期望受教育年限;3.38是截距,即那些父亲根本没有受过教育的受访者的期望受教育年限;0.687是斜率,即父亲受教育年限每增加一年受访者受教育年限的期望增加值。根据这个方程,我们预测父亲受过10年教育的受访者将会有10.25年的受教育年限,因为3.38+10×0.687=10.25。类似地,我们预测受过大学教育的人的子女的受教育年限比只受过高中教育的人的子女的受教育年限平均多2.75年,因为0.687×(16-12)=2.75。在给定自变量取值的情况下估计因变量的值被称为对方程求值。
1702646313
1702646314

1702646315
到目前为止,我们还没有讨论如何求方程5.2中的系数。在一组数据点中画出一条直线的标准是使预测误差的平方和最小——我们使观测值和预测值之间差异的平方和最小。用此方法得到的直线被称作常规最小二乘回归线(ordinary least-squares regression lines)。图5-3说明了此标准。图中所示的ei项(,即在给定他/她父亲的受教育年限时,第i个人的实际受教育年数减去此人的期望受教育年数)是特定数据点与回归线之间的预测误差。如果我们对每个预测误差〔也称残差(residuals)〕取平方并进行加总,就有且仅有一条使这个平方和最小的直线。这就是常规最小二乘(OLS)回归线。
1702646316
1702646317

1702646318
1702646319
1702646320
图5-3 受访者受教育年限与父亲受教育年限之间关系的最小二乘回归线,显示“预测误差”或“残差”是如何定义的
1702646321
1702646322
为什么用“最小平方”标准来确定拟合得最好的线? 注意,“最小平方”并不是“拟合得最好”的唯一合理标准。一个直觉上更有吸引力的标准是使观测值与期望值之间的绝对偏差之和最小。但是,绝对值在数学上是很难处理的,而平方和则具有方便的代数属性,这可能就是回归分析的发明者想到使偏差的平方和最小这个标准的原因。结果是,如果某些观测值异乎寻常地大幅度偏离数据固有的相关模式,那么回归估计值就会受到很大影响;因为偏差被取了平方,所以这些观测值具有最大的(影响)权重。因此,非典型观测值(本书称之为高杠杆点)的存在会导致非常具有误导性的结果。我们将在随后的段落和第10章中进一步讨论这一点。
1702646323
1702646324
用代数或微积分方法,可以证明下面的斜率和截距公式满足最小平方标准:
1702646325
1702646326

1702646327
1702646328
1702646329
1702646330
1702646331
1702646332
量化数据分析:通过社会研究检验想法 [:1702644751]
1702646333
量化数据分析:通过社会研究检验想法 评估某种关系的强度:相关分析
1702646334
1702646335
我们已经知道了如何得到回归线以及如何解释它们,现在我们需要评估预测的好坏程度。预测的好坏或拟合优度(goodness of fit)的标准是因变量方差能够被自变量方差所解释的部分或比例。我们定义
1702646336
1702646337

1702646338
1702646339