1700536289
百面机器学习:算法工程师带你去面试 [:1700532203]
1700536290
百面机器学习:算法工程师带你去面试 第7章 优化算法
1700536291
1700536292
优化是应用数学的一个分支,也是机器学习的核心组成部分。实际上,机器学习算法 = 模型表征 + 模型评估 + 优化算法。其中,优化算法所做的事情就是在模型表征空间中找到模型评估指标最好的模型。不同的优化算法对应的模型表征和评估指标不尽相同,比如经典的支持向量机对应的模型表征和评估指标分别为线性分类模型和最大间隔,逻辑回归对应的模型表征和评估指标则分别为线性分类模型和交叉熵。
1700536293
1700536294
随着大数据和深度学习的迅猛发展,在实际应用中面临的大多是大规模、高度非凸的优化问题,这给传统的基于全量数据、凸优化的优化理论带来了巨大的挑战。如何设计适用于新场景的、高效的、准确的优化算法成为近年来的研究热点。优化虽然是一门古老的学科,但是大部分能够用于训练深度神经网络的优化算法都是近几年才被提出,如Adam算法等。
1700536295
1700536296
虽然,目前大部分机器学习的工具已经内置了常用的优化算法,实际应用时只需要一行代码即可完成调用。但是,鉴于优化算法在机器学习中的重要作用,了解优化算法的原理也很有必要。
1700536297
1700536298
1700536299
1700536300
1700536301
百面机器学习:算法工程师带你去面试 [:1700532204]
1700536302
百面机器学习:算法工程师带你去面试 01 有监督学习的损失函数
1700536303
1700536304
1700536305
1700536306
场景描述
1700536307
1700536308
机器学习算法的关键一环是模型评估,而损失函数定义了模型的评估指标。可以说,没有损失函数就无法求解模型参数。不同的损失函数优化难度不同,最终得到的模型参数也不同,针对具体的问题需要选取合适的损失函数。
1700536309
1700536310
知识点
1700536311
1700536312
损失函数
1700536313
1700536314
问题 有监督学习涉及的损失函数有哪些?请列举并简述它们的特点。
1700536315
1700536316
难度:★☆☆☆☆
1700536317
1700536318
分析与解答
1700536319
1700536320

1700536321

1700536322

1700536323
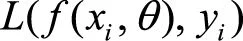
1700536324
在有监督学习中,损失函数刻画了模型和训练样本的匹配程度。假设训练样本的形式为(xi, yi),其中 xi∈X表示第i个样本点的特征,yi∈Y表示该样本点的标签。参数为θ的模型可以表示为函数,模型关于第i 个样本点的输出为。为了刻画模型输出与样本标签的匹配程度,定义损失函数,越小,表明模型在该样本点匹配得越好。
1700536325
1700536326
对二分类问题,Y={1,−1},我们希望sign f(xi,θ)=yi,最自然的损失函数是0-1损失,即
1700536327
1700536328

1700536329
1700536330
1700536331
(7.1)
1700536332
1700536333
其中1P是指示函数(Indicator Function),当且仅当P 为真时取值为1,否则取值为0。该损失函数能够直观地刻画分类的错误率,但是由于其非凸、非光滑的特点,使得算法很难直接对该函数进行优化。0-1损失的一个代理损失函数是Hinge损失函数:
1700536334
1700536335

1700536336
1700536337
1700536338
(7.2)