1700536301
百面机器学习:算法工程师带你去面试 [:1700532204]
1700536302
百面机器学习:算法工程师带你去面试 01 有监督学习的损失函数
1700536303
1700536304
1700536305
1700536306
场景描述
1700536307
1700536308
机器学习算法的关键一环是模型评估,而损失函数定义了模型的评估指标。可以说,没有损失函数就无法求解模型参数。不同的损失函数优化难度不同,最终得到的模型参数也不同,针对具体的问题需要选取合适的损失函数。
1700536309
1700536310
知识点
1700536311
1700536312
损失函数
1700536313
1700536314
问题 有监督学习涉及的损失函数有哪些?请列举并简述它们的特点。
1700536315
1700536316
难度:★☆☆☆☆
1700536317
1700536318
分析与解答
1700536319
1700536320

1700536321

1700536322

1700536323
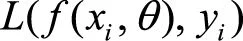
1700536324
在有监督学习中,损失函数刻画了模型和训练样本的匹配程度。假设训练样本的形式为(xi, yi),其中 xi∈X表示第i个样本点的特征,yi∈Y表示该样本点的标签。参数为θ的模型可以表示为函数,模型关于第i 个样本点的输出为。为了刻画模型输出与样本标签的匹配程度,定义损失函数,越小,表明模型在该样本点匹配得越好。
1700536325
1700536326
对二分类问题,Y={1,−1},我们希望sign f(xi,θ)=yi,最自然的损失函数是0-1损失,即
1700536327
1700536328

1700536329
1700536330
1700536331
(7.1)
1700536332
1700536333
其中1P是指示函数(Indicator Function),当且仅当P 为真时取值为1,否则取值为0。该损失函数能够直观地刻画分类的错误率,但是由于其非凸、非光滑的特点,使得算法很难直接对该函数进行优化。0-1损失的一个代理损失函数是Hinge损失函数:
1700536334
1700536335

1700536336
1700536337
1700536338
(7.2)
1700536339
1700536340
Hinge损失函数是0-1损失函数相对紧的凸上界,且当fy≥1时,该函数不对其做任何惩罚。Hinge损失在fy=1处不可导,因此不能用梯度下降法进行优化,而是用次梯度下降法(Subgradient Descent Method)。0-1损失的另一个代理损失函数是Logistic损失函数:
1700536341
1700536342

1700536343
1700536344
1700536345
(7.3)
1700536346
1700536347

1700536348
Logistic损失函数也是0-1损失函数的凸上界,且该函数处处光滑,因此可以用梯度下降法进行优化。但是,该损失函数对所有的样本点都有所惩罚,因此对异常值相对更敏感一些。当预测值时,另一个常用的代理损失函数是交叉熵(Cross Entropy)损失函数:
1700536349
1700536350
