1700538591
百面机器学习:算法工程师带你去面试 [:1700532225]
1700538592
百面机器学习:算法工程师带你去面试 06 深度残差网络
1700538593
1700538594
1700538595
1700538596
场景描述
1700538597
1700538598
随着大数据时代的到来,数据规模日益增加,这使得我们有可能训练更大容量的模型,不断地提升模型的表示能力和精度。深度神经网络的层数决定了模型的容量,然而随着神经网络层数的加深,优化函数越来越陷入局部最优解。同时,随着网络层数的增加,梯度消失的问题更加严重,这是因为梯度在反向传播时会逐渐衰减。特别是利用Sigmoid激活函数时,使得远离输出层(即接近输入层)的网络层不能够得到有效的学习,影响了模型泛化的效果。为了改善这一问题,深度学习领域的研究员们在过去十几年间尝试了许多方法,包括改进训练算法、利用正则化、设计特殊的网络结构等。其中,深度残差网络(Deep Residual Network,ResNet)是一种非常有效的网络结构改进,极大地提高了可以有效训练的深度神经网络层数。ResNet在ImageNet竞赛和AlphaGo Zero的应用中都取得了非常好的效果。图9.21展示了ImageNet竞赛在2010年—2015年的比赛时取得冠军的模型层数演化;在2015年时,利用ResNet训练的模型已达到152层,并且相较往年的模型取得了很大的精度提升。如今,我们可以利用深度残差网络训练一个拥有成百上千网络层的模型。
1700538599
1700538600

1700538601
1700538602
1700538603
图9.21 ImageNet竞赛历年冠军采用的模型和对应的效果
1700538604
1700538605
知识点
1700538606
1700538607
线性代数,深度学习
1700538608
1700538609
问题 ResNet的提出背景和核心理论是什么?
1700538610
1700538611
难度:★★★☆☆
1700538612
1700538613
分析与解答
1700538614
1700538615
ResNet的提出背景是解决或缓解深层的神经网络训练中的梯度消失问题。假设有一个L层的深度神经网络,如果我们在上面加入一层,直观来讲得到的L+1层深度神经网络的效果应该至少不会比L层的差。因为我们简单地设最后一层为前一层的拷贝(用一个恒等映射即可实现),并且其他层维持原来的参数即可。然而在进行反向传播时,我们很难找到这种形式的解。实际上,通过实验发现,层数更深的神经网络反而会具有更大的训练误差。在CIFAR-10数据集上的一个结果如图9.22所示,56层的网络反而比20层的网络训练误差更大,这很大程度上归结于深度神经网络的梯度消失问题[21]。
1700538616
1700538617

1700538618
1700538619
1700538620
图9.22 20层网络和56层网络在CIFAR-10数据集上的训练误差和测试误差
1700538621
1700538622
为了解释梯度消失问题是如何产生的。回顾第3节推导出的误差传播公式
1700538623
1700538624

1700538625
1700538626
1700538627
(9.43)
1700538628
1700538629
将式(9.31)再展开一层,可以得到
1700538630
1700538631

1700538632
1700538633
1700538634
(9.44)
1700538635
1700538636
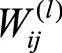
1700538637

1700538638

1700538639

1700538640
