1700508179
因此也叫作“几何间隔”。其中,||w||叫作“范数”,在欧式空间中的欧式范数定义为
1700508180
1700508181

1700508182
1700508183
1700508184
是向量的模。
1700508185
1700508186
几何间隔在空间几何上有具体的几何距离解释,这和我们在二维空间中求点到直线的距离及在三维空间中求点到平面的距离的计算方式是一样的。如果在规范化后,令||w||=1,间隔距离可以写作
1700508187
1700508188

1700508189
1700508190
1700508191
也叫作“函数间隔”。
1700508192
1700508193
定义一个训练集中的样本点到超平面wx+b=0几何距离最小的点
1700508194
1700508195

1700508196
1700508197
1700508198
所以,现在的问题就变成了怎样让γ最大化。
1700508199
1700508200
支持向量机学习的基本思路是,找到能够正确划分训练数据集且几何间隔最大的分离超平面。对线性可分的训练数据集来说,线性可分的分离超平面有无穷多个,但是几何间隔最大的分离超平面是唯一的。
1700508201
1700508202
“间隔最大化”又称“硬间隔最大化”,其直观解释是:对训练数据集找到几何间隔最大的超平面,意味着以充分大的确信度对训练数据进行分类,对最贴近超平面的点也有足够大的确信度将它们分开,以保证获得很好的分类预测能力。
1700508203
1700508204
在线性可分的情况下,训练数据集的样本点中与分离超平面距离最近的样本点的实例称为“支持向量”(Support Vector,如图11-34所示用圆圈标出的五角星和圆点)。
1700508205
1700508206
在SVM进行训练的过程中,会使用一种叫作“Hinge Loss”(也译作“合页损失函数”)的函数来充当损失函数。这个函数写作
1700508207
1700508208

1700508209
1700508210
1700508211

1700508212
1700508213
1700508214

1700508215

1700508216

1700508217

1700508218

1700508219

1700508220

1700508221

1700508222
前半部分很容易理解:如果分类预测与训练时的分类一致,其值就是的值就是0;相反,如果分类预测与训练时的分类不一致,其值就是的值就是1。后半部分叫作正则化项,λ是系数,叫作w的L2范数(实际上就是)。
1700508223
1700508224

1700508225
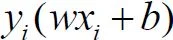
1700508226
正则化项在很多机器学习损失函数中都可以看到,这是一种为了降低结构风险而设置的“损失值”。由统计得到的这个部分的损失称为经验风险,后面的正则化项称为结构风险。尤其是在这种模型中,w按比例扩大不会影响分类结果,我们又希望得到一个w尽可能小的超平面描述来保证其简洁,且不会由于w过大而对噪声敏感进而产生过拟合现象。这种对模型进行优化的思路同样适用于其他分类模型。
1700508227
1700508228
