1702632071
1702632072
在实验完全不切合实际时,实验数据无法告诉我们,实验结论是否具有推广价值。实验人员如果想把实验结果从实验室中的学生推广至真实世界中的上班族,就必须用他们“对人的行为的了解”来说服大家,而不是只用数据。要想把实验结果从实验室中的老鼠推广至真实世界中的人,将会难上加难。因此,即使实验设计的逻辑非常有说服力,仅靠一个实验也不可能让人完全信服。新发现必须在不同环境中经过多次实验的检验,才能找到真正的适用范围。
1702632073
1702632074
实验能否产生有用的信息,以及能否让人信服,这不是由统计数据决定,而是由实验人员对实验主题所属领域的知识的掌握情况来决定的。避免产生隐性偏差所需要注意的一些细节,也依赖于实验人员对实验主题所属领域知识的了解。好的实验必须建立在统计原则和对研究领域的了解的基础上。
1702632075
1702632076
真实世界中的实验设计
1702632077
1702632078
我们见过的实验设计都遵循同样的模式:先对实验对象进行随机分组,组数和处理方法的数量相同,然后每组采用一种处理方法。这种设计模式叫作“完全随机化设计”(completely randomized design)。
1702632079
1702632080
完全随机化设计
1702632081
1702632082
在完全随机化设计的实验中,所有的实验对象都会被随机分配到某个组中,对应某种处理方式。
1702632083
1702632084
此外,到现在为止,我们所举的例子当中都只有一个解释变量(新药或者在线学习)。而完全随机化设计的实验可能有任意数目的解释变量。
1702632085
1702632086
知识普及 元分析
1702632087
1702632088
对一个重要问题只做一次实验,很难因此下结论。通常实验人员会做多次实验,它们的环境不同,设计不同,质量也不一样。我们能不能把不同实验的结果整合在一起,当作一个整体的结论呢?这就是“元分析”(meta-analysis)的概念。当然,各个实验之间的差异,使得我们无法直接把结果拼凑在一起。统计学家会用更加复杂的方法来整合结论,比如,元分析曾被用在二手烟的影响,以及补习是否可以提高美国学术能力评估测试的分数这些问题的研究中。
1702632089
1702632090
例8 低脂肪食品标签会导致肥胖症吗?
1702632091
1702632092
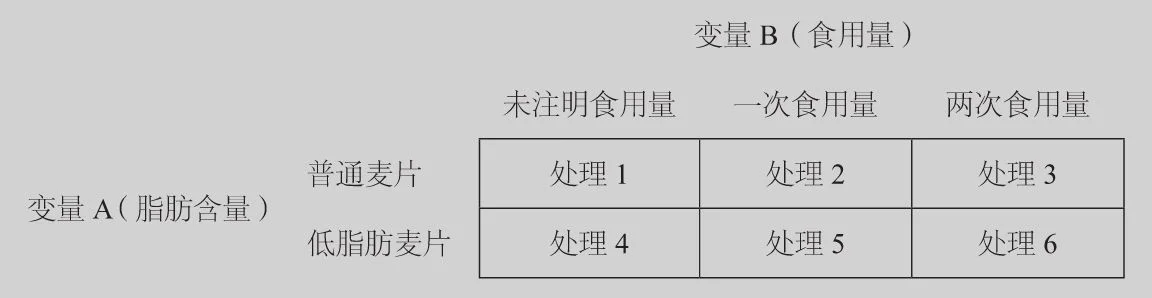
低脂肪食品标签对于食品消费的影响有多大?是否贴上低脂肪食品标签,人们就会吃掉更多的点心?答案可能取决于标签上是否有该食品是低脂肪食品以及关于食用量的信息。一项以大学员工、研究生和本科生作为实验对象的大型实验研究了这个问题。在十几个午后时段,所有实验对象都要在学校剧场里看60分钟电视节目,然后给节目打分。他们还被告知由于时间较晚,每个人会得到一瓶720毫升的冰水和一袋由受学生欢迎的校园餐厅Spice Box提供的格兰诺拉麦片,他们可以自己决定食用量。每名实验对象都拿到了一袋贴有3.25英寸×4英寸彩色标签的密封食品,上面注明这是一袋含有640卡路里热量(重量为160克)的格兰诺拉麦片。实验人员随机分配给实验对象的密封食品袋的不同之处在于,一种的标签上有“普通落基山格兰诺拉麦片”字样,另一种的标签上有“低脂肪落基山格兰诺拉麦片”字样。另外,有的标签上写着“内含一次食用量”、“内含两次食用量”,或者未注明食用量。当实验对象离开剧场时,他们被问及拿到的密封食品袋里的麦片是多大的食用量。在实验对象不在场的情况下,实验人员称了每一袋麦片的重量。实验对象的回答和称量结果是反应变量。
1702632093
1702632094
这个实验中有两个解释变量:脂肪含量,两种;食用量,3种。这可以组合成6种处理方式,见图6–1。
1702632095
1702632096
1702632097
1702632098
1702632099
图6–1 例8中的两个解释变量共组合出6种处理方式
1702632100
1702632101
练习
1702632102
1702632103
6.1 美味的蛋糕。一家食品公司准备推出一种什锦蛋糕,关键问题在于不能让蛋糕受到烘焙时间或温度变化的影响。在一个实验中,分别用148、160和171摄氏度将蛋糕烘焙1小时或1小时15分钟。用不同时间和不同温度的组合来制作蛋糕,每种处理方式对应10个蛋糕,由一组试吃者为每种蛋糕的口感和味道打分。
1702632104
1702632105
在这个实验中,解释变量和反应变量是什么?
1702632106
1702632107
画一个类似图6–1的图,展示该实验的处理方式。有多少种处理方式?需要制作多少个蛋糕?
1702632108
1702632109
实验人员经常希望能同时研究好几个变量的“联合效应”(combined effect)。几个因素的相互作用所产生的效应,无法根据每个因素的单独效应预测出来。长一点儿的广告也许会使观众对产品的兴趣增加,多播几次广告也许会使观众对产品的兴趣增加,但是如果我们既将广告加长,又多播几次,观众可能就会因厌烦而减少对产品的兴趣。例8的实验会帮我们找到答案。
1702632110
1702632111
配对设计与区块设计
1702632112
1702632113
完全随机化设计的实验是统计实验中最简单的一种,这类设计清楚地展示了控制与随机化这两项原则,不过,它往往比不上一些更复杂的设计。准确地说,用各种方式对实验对象做一些配对操作,得到的结果会比只进行随机化操作更精确。
1702632114
1702632115
兼具配对和随机化操作的常用设计就是“配对设计”(matched pairs design),配对设计只比较两种处理方式。先对实验对象进行配对操作,配对的两个实验对象在各方面应尽量相似。然后,利用抛硬币的方式,或者根据从表A中读取的随机数字为奇数或偶数来决定,把两种处理方式分别指派给配对的两个实验对象。有时候配对设计中的“一对实验对象”,实际上只包括一个实验对象,只是先后采取两种处理方式。此时,每个实验对象就是他/她自己的控制组。采取不同处理方式的顺序可能会影响实验对象的反应,所以会用抛硬币的方式来对每个实验对象采取不同处理方式的顺序进行随机化。
1702632116
1702632117
例9 可口可乐与百事可乐
1702632118
1702632119
百事可乐公司想要证明,可口可乐的爱好者在盲品两种可乐时,会更偏爱百事可乐。实验对象都是声称自己爱喝可口可乐的人,他们喝完两个未标示品牌的玻璃杯中的可乐之后,要说出更喜欢哪一杯。这就是配对设计:每个实验对象喝两种可乐,并做出比较。因为实验对象的反应和先喝哪种可乐有关,所以喝可乐的顺序应该随机化。
1702632120