1702638879

1702638880
•的分布接近于正态分布。
1702638881
1702638882
• 抽样分布的平均数和p相等。
1702638883
1702638884
• 抽样分布的标准差是:
1702638885
1702638886
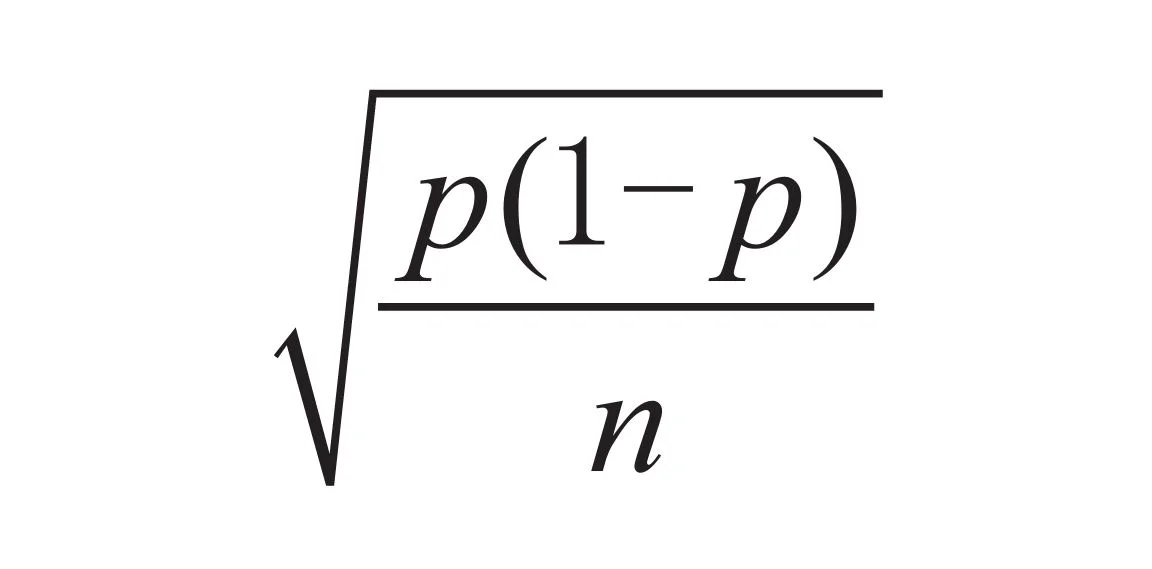
1702638887
1702638888
1702638889
这些事实是可以用数学方法证明的,所以基础很坚实。图21-1把这些事实用某种形式进行了整合,这提醒我们:抽样分布描述的是从同一总体中抽出的许多样本的结果。
1702638890
1702638891

1702638892
1702638893
1702638894
图21-1 从一个成功比例为p的总体中抽取大小为n的简单随机样本,重复抽取许多次。样本统计量的值呈正态分布
1702638895
1702638896
例2 酗酒问题
1702638897
1702638898
1702638899
假设12%是2010年加州全体大学生的酗酒人数比例,那么在例1中,p=0.12。BRFSS的样本大小n=6911,如果重复抽样很多次,样本比例会很接近正态分布,其平均数=p=0.12。
1702638900
1702638901

1702638902
1702638903
1702638904
1702638905
这个正态分布的中心是对这个总体的正确描述。由于样本非常大,所以标准差很小,几乎所有样本都将产生一个非常接近真实参数p的统计量。根据68-95-99.7规则,95%的样本统计量将落在平均数减去两个标准差(0.12-0.0078=0.1122)和平均数加上两个标准差(0.12+0.0078=0.1278)的区间内。见图21-2。
1702638906
1702638907

1702638908
1702638909
1702638910
图21-2 从成功比例p=0.12的总体中抽取大小为6911的简单随机样本许多个,95%的样本统计量会落在0.1122~0.1278的区间内
1702638911
1702638912
1702638913
1702638914
到目前为止,我们只不过是用数字把我们已经知道的事实表达出来:我们可以信任大的随机样本的结果,因为几乎所有这类样本的统计量的值都很接近总体参数的真实值。数字告诉我们,大小为6911的所有样本中的95%,其统计量和参数p的值的差距不大于0.0078。也可以说,在所有样本中,有95%的值落在p-0.0078到p+0.0078之间。
1702638915
1702638916
1702638917
0.0078是把p=0.12代入的标准差公式中得来的。对于任意p来说,一般事实如下:
1702638918
1702638919
1702638920
当总体参数的值为p时,有95%的样本统计量的值落在p值往左右各延伸两个标准差的区间内。
1702638921
1702638922
上面说的区间是:
1702638923
1702638924

1702638925
1702638926
1702638927
这是不是我们要的95%置信区间呢?不能肯定。这个区间没有办法根据样本数据算出来,因为标准差公式里有总体参数p,而实际上我们并不知道p的值。在例2里我们把p=0.12代入该公式,但这并不一定是p的真实值。
1702638928