1702639635
抽样分布。如果零假设为真,样本平均数大致一个平均数μ=290,标准差的正态分布。我们用样本标准差s代替未知的总体标准差σ。
1702639636
1702639637

1702639638
数据。NAAL的样本给出了=276,所以标准分是:
1702639639
1702639640

1702639641
1702639642
1702639643
也就是说,样本的结果距离平均分约5.83个标准差,一般而言,达到平均分的年轻人才具备记账的技能。
1702639644
1702639645
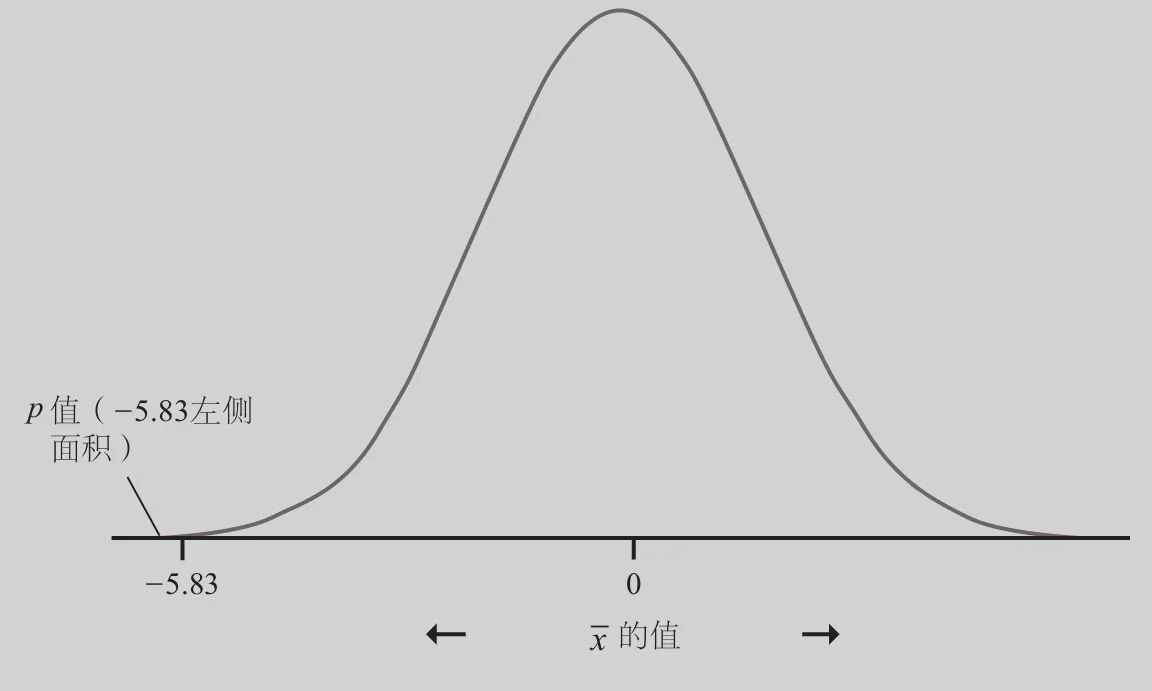
P值。图22-4在正态分布曲线上标示了样本结果-5.83(以标准差为单位刻度),该正态分布曲线代表零假设为真时的抽样分布。由于我们使用的是标准差,因此这条曲线的平均数为0,标准差为1。我们单边检验的P值是该正态分布曲线上-5.83左侧的面积,图22-4显示这个面积非常小。表B的最小值是-3.4,从表B中看到-3.4就是第0.03百分位数,所以其左侧面积是0.0003。由于-5.83比-3.4小,所以我们知道其左侧面积要比0.0003还小。所以,我们的P值小于0.0003。
1702639646
1702639647
1702639648
1702639649
1702639650
图22-4 样本平均数的标准分是-5.83时的单边检验的P值
1702639651
1702639652
结论。小于0.0003的P值是一个很有说服力的证据,证明年轻人(19~24岁)的平均分低于记账所要求的知识水平。
1702639653
1702639654
知识普及 抓住作弊者
1702639655
1702639656
很多学生都参加过有许多道选择题的考试。为试卷打分的计算机是否可以筛选出那些答案看上去很类似的试卷呢?聪明的人类已经创造了一种方法,不仅能看答案是否一样,而且会看相同答案的普遍程度,以及相似试卷的总分数。这个方法接近于正态分布,计算机能用这种方法把超出±4个标准差的类似试卷筛选出来。
1702639657
1702639658
例5 经理人的收缩压
1702639659
1702639660
1702639661
全美健康统计中心报告35~44岁男性的平均收缩压是128。一家大型企业的医务总监查阅了这个年龄段72名经理人的医疗记录,发现这个样本的收缩压平均数=126.1,标准差s=15.2。这能否作为一个证明该公司的经理人与一般公众的平均收缩压不一样的证据?
1702639662
1702639663
假设。零假设是该公司经理人的平均收缩压与全国平均数“无差异”。备择假设是双边的,因为该医务总监在查阅这些数据之前,心里并没有特定的倾向。所以,有关经理人总体收缩压的未知平均数μ的假设是:
1702639664
1702639665
H0:μ=128
1702639666
1702639667
Ha:μ≠128
1702639668
1702639669
1702639670

1702639671
抽样分布。如果零假设为真,样本平均数大致是一个平均数μ=128,标准差的正态分布。
1702639672
1702639673
1702639674
数据。样本平均数=126.1,其标准分是:
1702639675
1702639676

1702639677
1702639678
1702639679
我们知道,一个和正态分布平均数之间的距离略超过1个标准差的样本结果并不值得人们大惊小怪。
1702639680
1702639681
P值。图22-5在正态分布曲线上标示出样本结果-1.06(以标准差为单位刻度),该曲线代表零假设为真时的抽样分布。这个双边P值表明,结果的概率在两个方向上都偏离得很远,见曲线下方的阴影面积。用表B,将标准分四舍五入为-1.1,这是正态分布的第13.57百分位数。所以,-1.1左边的面积是0.1357。两边的面积一样大,加总后约为0.27,这就是我们粗略估算出的P值。
1702639682
1702639683
结论。P值较大,这让我们没理由认为经理人群体的平均收缩压与一般大众的平均水平不同。
1702639684